Eksik verilere atama yapmadan önce bu verileri dikkatlice inceleyin. Eksik verilerin neden oluştuğunu, nasıl dağıldığını ve analizlerinizi nasıl etkileyebileceğini anlamak, doğru yöntemleri seçmek için gerekli. Bu inceleme, eksik verilerin tesadüfi mi yoksa sistematik mi olduğunu belirlemenize ve uygun çözüm stratejilerini seçmenize yardımcı olur.
İncelemeye eksik verinin oranını belirleyerek başlayalım. Eksik verinin hangi oranda kabul edilebilir olduğu, yapılan çalışmanın türüne, veri setinin büyüklüğüne ve analiz yöntemlerine bağlı olarak değişir. Ancak genel olarak kabul gören koşulları açıklayalım.
%5 ve Altı: Eksik veri oranı %5’in altındaysa, bu genellikle kabul edilebilir. Bu durumda, eksik verilerin analizler üzerindeki etkisi azdır ve genellikle basit yöntemler (örneğin, silme veya ortalama ile doldurma) tercih edilebilir.
%5-10 Arası: Bu aralık, dikkatli olunması gereken bir bölgedir. Eksik verilerin neden kaynaklandığını ve nasıl dağıldığını incelemek önemlidir. Eksik verilerin tesadüfi olup olmadığı kontrol edilmeli ve uygun tamamlama yöntemleri kullanılmalıdır.
%10 ve Üzeri: Eksik veri oranı %10’u aştığında, bu durum analizlerin güvenirliğini ciddi şekilde etkileyebilir. Bu tür durumlarda, eksik verilerin nedenleri incelenmeli ve gelişmiş tamamlama yöntemleri kullanılmalıdır. Ayrıca, eksik verilerin analiz sonuçlarını nasıl etkilediğine dair duyarlılık analizleri yapılmalıdır.
Eksik verinin oranını SPSS’te frekans analizi yaparak belirleyebilirsiniz.
Analyze → Descriptive Statistics → Frequencies yolunu takip edebilirsiniz. SPSS’i ilk kez kullananlar için örnek gösterimleri içeren görseller ekledim.
Analizin sonunda eksik verinin oranını çıktı dosyasında görebilirsiniz. Aşağıda örnek verdim.
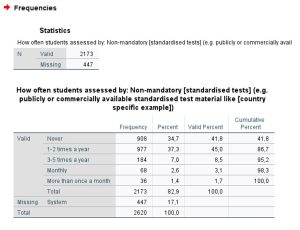
Bu örnek için 2620 veriden, 447’si yani %17,1’i eksik. Bu oran eksik veriyle çalışıldığı durumda sonuçların genellenebilirliğini düşürecek önemli bir soruna yol açacaktır. Bu inceleme işlemini tüm verileriniz için tek tek yapmalısınız.
Eksik verinin bulunduğu değişkenin kategorik ya da sürekli olması farklı inceleme yöntemlerini ve farklı atama yöntemlerini gerektirir. Bu nedenle bundan sonraki yazılarda bu konuyu ayrı ayrı ele aldım. Eksik verilerin oranlarını belirledikten sonra araştırma sorularınızla ilgili değişkenlerde eksik verilerin gruplara ya da kategorilere nasıl dağıldığını incelemelisiniz.
Eksik verilerin belirli kategorilerde yoğunlaşması, eksik verilerin tümüyle tesadüfi/rastgele olmadığını (MNAR – Missing Not at Random) veya diğer gözlenen değişkenlerle ilişkili (MAR – Missing at Random) olabileceğini düşündürür. Yazının bundan sonraki kısmında karışıklığa yol açmamak için eksik verinin dağılımıyla ilgili olarak MAR ve MNAR kavramlarını kullanmayı tercih ediyorum.
Eksik Veride MAR
Eksik veride MAR olması, eksik verinin gözlemlenebilir verilere bağlı olarak sistematik bir şekilde dağıldığı durumu ifade eder. Yani, eksik verilerin nerede ve nasıl oluştuğu, veri setindeki diğer gözlemlenebilir değişkenlerle ilişkilidir, ancak eksik verinin kendisiyle değil. Bunu bir örnekle açıklayım. Sağlık alanında bir araştırma yürütüldüğünü varsayalım. Katılımcıların yaşları, cinsiyetleri ve kan basınçları soruluyor. Yaşlı katılımcılar kan basıncı ölçümlerini hatırlayamıyor ve bu bilgiler veri setinde eksik kalıyor. Bu durumda, eksik veriler rastgele değildir, yaş gibi gözlemlenebilir bir değişkene bağlıdır. Bu durum eksik verilerin tahmin edilebilir olmasını sağlar. Eksik verilere atama yapılabilir.
Sonuç olarak eksik veriler, veri setindeki diğer değişkenlerle (örneğin, yaş, cinsiyet, gelir düzeyi) ilişkilidir ancak eksik olan değişkenin kendisiyle (örneğin, kan basıncının gerçek değeriyle) ilişkili değildir. MAR durumunda, eksik verilerin nerede ve nasıl oluştuğu, diğer gözlemlenebilir değişkenler kullanılarak tahmin edilebilir.
Eksik Veride MNAR
Eksik verilerin, eksik olan değişkenin kendisiyle veya gözlemlenemeyen faktörlerle ilişkili olduğu durumu ifade eder. Örneğin, HIV virüsü taşıyan kişilerin sağlıkla ilgili araştırmalarda bu bilgiyi paylaşmaktan kaçınması gibi. Bu durum sonuçlarda sistematik bir farka yol açabilir. Bu durumda, standart veri atama yöntemleri yanlı tahminler üretebilir ve veri analizinin doğruluğunu düşürebilir. Bu tür durumlarda araştırmanın doğası, örneklem büyüklüğü, ölçülen özellik gibi çok sayıda faktör dikkate alınarak karar verilmelidir. Eksik verinin rastgele olmadığı durumlarda tek bir doğru yol ya da yöntemden söz etmek uygun olmaz.
Doç. Dr. Fatma Betül KURNAZ