Kategorik değişkenlerde eksik veri ile diğer değişkenlerin ilişkisini görmek için çapraz tablolar oluşturabilirsiniz. Öncelikle hangi değişkenlerde ne kadar eksik veri olduğunu frekans analizi ya da çapraz tablolar yoluyla inceleyin. Hangi değişkenlerde eksik veri olduğunu not alın. SPSS kullanarak kategorik verilerde eksik veriyi nasıl inceleyebileceğinize ilişkin işlem adımlarını açıkladım.
Adımlar:
Analyze → Descriptive Statistics → Crosstabs.
Rows (Satırlar) ve Columns (Sütunlar) bölümlerine kategorik değişkenlerinizi taşıyın. Eksik değerlere sahip kategorik değişkenleri analiz etmek için değişkenleri seçin.
Cells altında Missing Values seçeneğini işaretleyin. Açılan pencerede:
-
-
-
- Observed (Gözlenen) ve Missing (Eksik) kutucuklarını işaretleyin.
- Bu, eksik değerlerin de tabloya dahil edilmesini sağlar. Continue (Devam) ve ardından OK düğmesine tıklayın. Sonuçları İnceleyin
-
-
Çapraz tablo sonuçlarında eksik değerler genellikle “System Missing” (Sistemsel Eksik) veya tanımlı bir eksik değer kodu (örneğin, -9) olarak bir kategori halinde gösterilir. Aşağıdaki örnek çıktıları inceleyelim.

Bu örnekte cinsiyet ve dil değişkenlerinin eksik veri oranı %5 olarak belirlenmiştir. Bu kabul edilebilir bir oran olarak değerlendirilebilir.
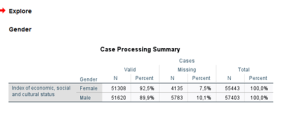
Bu örnekte ise eksik verilerin erkek katılımcılardaki oranının kadın katılımcılara göre daha yüksek olduğu görülmektedir. Bu durumda analiz sonuçlarının gerçeği yansıtmama olasılığı mümkün. Sonuçlar sistematik bir hataya neden olabilir. Eksik değerlerin belirli kategorilerde yoğunlaşması, eksik verilerin tümüyle rastlantısal olmadığını (MNAR – Missing Not at Random) veya diğer gözlenen değişkenlerle ilişkili (MAR – Missing at Random) olabileceğini düşündürür. Bu durumda eksik verilerin o grupta (örneğin bu görselde erkek katılımcılar) neden daha fazla olduğunu düşünmek ve bunu gerekçelendirmek gerekebilir. Eğer gerekçelendiremiyorsak ve analize bu şekilde devam etmekten başka bir yolumuz da yoksa bu durumu araştırmanın sınırlılıklarına yazmamız araştırmamıza güven duyulabilirliği artırabilir.
Eksik verilerin sistematik (yanlı) dağılımı, eksikliklerin rastgele olmadığı ve belirli bir nedene veya örüntüye bağlı olarak ortaya çıktığı durumu ifade eder. Bu tür eksik veriler, veri setindeki diğer değişkenlerle veya gözlemlerle ilişkili olabilir. Bunu bir örnekle açıklayalım.
Bir seçim öncesi anket çalışması yaptığınızı düşünün. Ankette, katılımcılara hangi partiye oy verecekleri ve hükümetin ekonomi politikaları hakkında ne düşündükleri soruluyor. Muhalefet partisine oy verecek katılımcıların, hükümetin ekonomi politikaları hakkında olumsuz görüşlere sahip olduğunu, ancak bu görüşlerini paylaşmaktan çekindiğini varsayalım. Örneğin, “Bu konuda yorum yapmak istemiyorum” diyerek soruyu atlayabilirler. İktidar partisine oy verecek katılımcılar ise ekonomi politikaları hakkında daha açık ve olumlu görüşlerini paylaşabilir. Bu durumda, eksik veriler (hükümetin ekonomi politikalarıyla ilgili görüşler) sistematik olarak dağılmıştır çünkü eksiklikler, katılımcıların siyasi tercihleriyle ilişkilidir. Yani, muhalefet taraftarları bu soruları boş bırakırken, iktidar taraftarları bu soruları cevaplamıştır. Eksik verileri silerseniz veya göz ardı ederseniz, analizlerinizde muhalefet taraftarlarının görüşleri yeterince temsil edilmez. Bu durum, hükümetin ekonomi politikalarına ilişkin genel kamuoyu algısının olduğundan daha olumlu çıkmasına neden olabilir. Yani, sonuçlarda yanlılık ortaya çıkar ve sonuçlar gerçeği yansıtmaz.
Eksik Verilerin Rastlantısal (MAR) Olması
Verinin rastlantısal eksik (MAR – Missing at Random) olması, gözlemlenebilir verilere bağlı olarak sistematik bir şekilde dağıldığı durumu ifade eder. Yani, eksik verilerin nerede ve nasıl oluştuğu, veri setindeki diğer gözlemlenebilir değişkenlerle ilişkilidir, ancak eksik verinin kendisiyle değil. Bunu bir örnekle açıklayım. Sağlık alanında bir araştırma yürütüldüğünü varsayalım. Katılımcıların yaşları, cinsiyetleri ve kan basınçları soruluyor. Yaşlı katılımcılar kan basıncı ölçümlerini hatırlayamıyor ve bu bilgiler veri setinde eksik kalıyor. Bu durumda, eksik veriler rastgele değildir, yaş gibi gözlemlenebilir bir değişkene bağlıdır. Bu durum eksik verilerin tahmin edilebilir olmasını sağlar. Eksik verilere atama yapılabilir.
Sonuç olarak eksik veriler, veri setindeki diğer değişkenlerle (örneğin, yaş, cinsiyet, gelir düzeyi) ilişkilidir ancak eksik olan değişkenin kendisiyle (örneğin, kan basıncının gerçek değeriyle) ilişkili değildir. MAR durumunda, eksik verilerin nerede ve nasıl oluştuğu, diğer gözlemlenebilir değişkenler kullanılarak tahmin edilebilir.
Eksik Verinin Rastlantısal Olmaması (Missing Not at Random – MNAR)
Eksik verilerin, eksik olan değişkenin kendisiyle veya gözlemlenemeyen faktörlerle ilişkili olduğu durumu ifade eder. Örneğin, düşük kan basıncına sahip kişilerin bu bilgiyi paylaşmaktan kaçınması gibi. Bu durum sonuçlarda sistematik bir farka yol açabilir. Bu durumda, standart veri atama yöntemleri yanlı tahminler üretebilir ve veri analizinin doğruluğunu düşürebilir. Bu tür durumlarda araştırmanın doğası, örneklem büyüklüğü, ölçülen özellik gibi çok sayıda faktör dikkate alınarak karar verilmelidir. Eksik verinin rastlantısal olmadığı durumlarda tek bir doğru yol ya da yöntemden söz etmek uygun olmaz.